编译原理布置了一个巨复杂的作业,完成一个简单函数绘图语言的解释器,秉承某电实验班的开源精神~在此记录一下方便后人。

运行环境:Visual Studio 2019
简单函数绘图语言的解释器可分为:词法分析器、语法分析器、语义分析器三部分实现。代码组织框架如下图所示: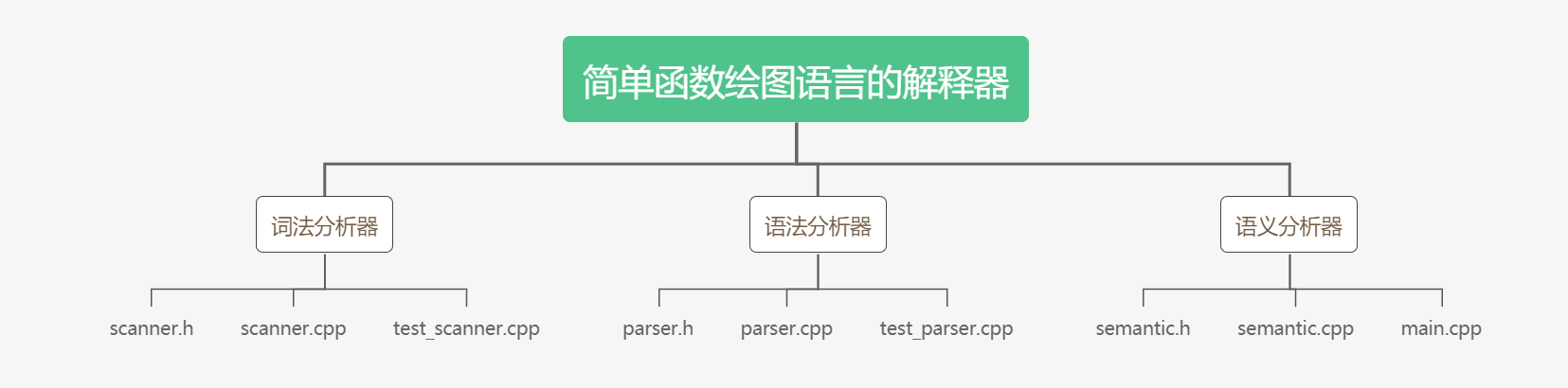
1、词法分析器
测试文本:
test_scanner.txt
ORIGIn IS (350, 220);
rot is 0;
scale is (50, 100);
FOR T FROM 0 TO 2*PI STEP PI/500 DRAW(cos(T),sin(T));
scale is (100, 100);
FOR T FROM 0 TO 2*PI STEP PI/500 DRAW(cos(2*T),sin(T));scanner.h
#ifndef SCANNER_H
#define SCANNER_H
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <ctype.h> //ctype.h是C标准函数库中的头文件,定义了一批C语言字符分类函数,用于测试字符是否属于特定的字符类别,
//如字母字符、控制字符等等。
#include <stdarg.h>//让函数可以接收可变参数
#include <math.h>
enum Token_Type//记号类别枚举
{
ORIGIN/* 0 */, SCALE/* 1 */, ROT/* 2 */, IS/* 3 */, TO/* 4 */, STEP/* 5 */, DRAW/* 6 */, FOR/* 7 */, FROM/* 8 */,//保留字
T/* 9 */,//参数
SEMICO/* 10 */, L_BRACKET/* 11 */, R_BRACKET/* 12 */, COMMA/* 13 */,//分层符号
PLUS/* 14 */, MINUS/* 15 */, MUL/* 16 */, DIV/* 17 */, POWER/* 18 */,//运算符
FUNC/*19 */,//函数
CONST_ID/* 20 */,//常数
NONTOKEN/* 21 */,//空记号,标记源程序文件的结束
ERRTOKEN/* 22 *///出错记号,标记非法输入
};
typedef double(*MathFuncPtr)(double);//MathFuncPtr代表一个指向返回double值并带有一个double形参的函数的指针的类型
struct Token
{
Token_Type type;//记号类别
char * lexeme;//属性,字符串,指向char类型的指针
double value;//属性,常数的值,double型
double(*FuncPtr)(double);//属性,函数指针,代表一个指向返回double值并带有一个double形参的函数的指针的类型
};
static Token TokenTab[] = //符号表内容
{
{ CONST_ID, (char*)"PI", 3.1415926, NULL },
{ CONST_ID, (char*)"E", 2.71828, NULL },
{ T, (char*)"T", 0.0, NULL },
{ FUNC, (char*)"SIN", 0.0, sin },
{ FUNC, (char*)"COS", 0.0, cos },
{ FUNC, (char*)"TAN", 0.0, tan },
{ FUNC, (char*)"LN", 0.0, log },
{ FUNC, (char*)"EXP", 0.0, exp },
{ FUNC, (char*)"SQRT", 0.0, sqrt },
{ ORIGIN, (char*)"ORIGIN", 0.0, NULL },
{ SCALE, (char*)"SCALE", 0.0, NULL },
{ ROT, (char*)"ROT", 0.0, NULL },
{ IS, (char*)"IS", 0.0, NULL },
{ FOR, (char*)"FOR", 0.0, NULL },
{ FROM, (char*)"FROM", 0.0, NULL },
{ TO, (char*)"TO", 0.0, NULL },
{ STEP, (char*)"STEP", 0.0, NULL },
{ DRAW, (char*)"DRAW", 0.0, NULL },
};
extern unsigned int LineNo;//跟踪记号所在源文件行号
extern int InitScanner(const char *);//初始化词法分析器
extern Token GetToken(void);//获取记号函数
extern void CloseScanner(void);//关闭词法分析器
#endif#pragma once
#pragma once
scanner.cpp
#include "scanner.h"
#define TOKEN_LEN 100//记号最大长度
#pragma warning(disable: 4996)
unsigned int LineNo;//源文件行号
static FILE *InFile;//输入文件流
static char TokenBuffer[TOKEN_LEN];//记号字符缓冲
//初始化词法分析器
extern int InitScanner(const char *FileName)
{
LineNo = 1;//行号
InFile = fopen(FileName, "r");//只读形式打开文件
if (InFile != NULL) return 1;//打开成功
else return 0;//打开失败
}
//关闭词法分析器
extern void CloseScanner(void)
{
if (InFile != NULL)
fclose(InFile);//关闭文件
}
//从输入源程序(流)读字符
static char GetChar(void)
{
char Char = getc(InFile);//逐个字符读
return toupper(Char);//全部转换为大写,然后return
}
//将预读字符退回源程序(流)
static void BackChar(char Char)
{
if (Char != EOF)
ungetc(Char, InFile);
}
//加入字符到记号缓冲区
static void AddCharTokenString(char Char)
{
int TokenLength = strlen(TokenBuffer);
if (TokenLength + 1 >= sizeof(TokenBuffer)) return;//数组越界
TokenBuffer[TokenLength] = Char;//写入字符到缓冲区
TokenBuffer[TokenLength + 1] = '\0';//加入字符串结束标志“\0”
}
//请空记号缓冲区
static void EmptyTokenString()
{
memset(TokenBuffer, 0, TOKEN_LEN);
}
//判断记号是否在记号表中
static Token JudgeKeyToken(const char *IDString)
{
int loop;
//sizeof(TokenTab)L:表示这个数组一共占了多少字节数;sizeof(TokenTab[0]):表示一个元素所占的字节数,两者相除,表述数组中一共有多少个元素
for (loop = 0; loop < sizeof(TokenTab) / sizeof(TokenTab[0]); loop++)
{ //遍历TokenTab表
if (strcmp(TokenTab[loop].lexeme, IDString) == 0)
return TokenTab[loop];//判断在字符表中就返回该记号
}
Token errortoken;
memset(&errortoken, 0, sizeof(Token));//先将errortoken置空
errortoken.type = ERRTOKEN;//然后填入出错记号
return errortoken;//返回出错记号
}
//获得一个记号
extern Token GetToken(void)
{
Token token;
char Char;
memset(&token, 0, sizeof(Token));//token置空
EmptyTokenString();//清空记号缓冲区
token.lexeme = TokenBuffer;
for (;;)//此循环用来过滤掉源程序中的空格、TAB、回车等分隔符,文件结束返回空记号
{
Char = GetChar();//从源程序读字符
if (Char == EOF)//读出错
{
token.type = NONTOKEN;
return token;
}
if (Char == '\n')
LineNo++;//行号+1
if (!isspace(Char))//遇到空格该记号肯定已经完成,退出循环
break;
}
AddCharTokenString(Char);//如果不是上面的那些分隔符,就先加入缓冲区
if (isalpha(Char))//如果是英文字母,一定是函数、关键字、PI、E等
{
for (;;)
{
Char = GetChar();
if (isalnum(Char))//如果是字母或数字
AddCharTokenString(Char);//加入缓冲区
else break;
}
BackChar(Char);//退回缓冲区
token = JudgeKeyToken(TokenBuffer);//判断是否在记号表中
token.lexeme = TokenBuffer;
return token;
}
else if (isdigit(Char))//如果是数字,一定是常量
{
for (;;)
{
Char = GetChar();
if (isdigit(Char))
AddCharTokenString(Char);
else break;
}
if (Char == '.')
{
AddCharTokenString(Char);
for (;;)
{
Char = GetChar();
if (isdigit(Char))
AddCharTokenString(Char);
else break;
}
}
BackChar(Char);
token.type = CONST_ID;
token.value = atof(TokenBuffer);
return token;
}
else//如果是其他符号
{
switch (Char)
{
case ';': token.type = SEMICO; break;
case '(': token.type = L_BRACKET; break;
case ')': token.type = R_BRACKET; break;
case ',': token.type = COMMA; break;
case '+': token.type = PLUS; break;
case '-':
Char = GetChar();
if (Char == '-')
{
while (Char != '\n' && Char != EOF) Char = GetChar();
BackChar(Char);
return GetToken();
}
else
{
BackChar(Char);
token.type = MINUS;
break;
}
case '/':
Char = GetChar();
if (Char == '/')
{
while (Char != '\n' && Char != EOF) Char = GetChar();
BackChar(Char);
return GetToken();
}
else
{
BackChar(Char);
token.type = DIV;
break;
}
case '*':
Char = GetChar();
if (Char == '*')
{
token.type = POWER;
break;
}
else
{
BackChar(Char);
token.type = MUL;
break;
}
default:token.type = ERRTOKEN; break;
}
}
return token;
}test_scanner.cpp
#include "scanner.h"
int main()
{
Token token;
FILE *fp;
InitScanner("test_scanner.txt");
printf("记号类型 字符串 常数值 函数指针\n");
printf("------------------------------------------\n");
while (1)
{
token = GetToken();//获得记号
if (token.type != NONTOKEN)//打印记号内容
printf("%4d,%12s,%12f,%12x\n", token.type, token.lexeme, token.value, token.FuncPtr);
else break;
}
printf("------------------------------------------\n");
CloseScanner();
}2、语法分析器
测试文本:
test_parser.txt
ORIGIn IS (350, 220);
rot is 0;
scale is (50, 100);
FOR T FROM 0 TO 2*PI STEP PI/500 DRAW(cos(T),sin(T));
scale is (100, 100);
FOR T FROM 0 TO 2*PI STEP PI/500 DRAW(cos(2*T),sin(T));Parser.h
#ifndef PARSER_H
#define PARSER_H
#include"scanner.h"
typedef double(*FuncPtr)(double);
struct ExprNode //语法树节点类型
{
enum Token_Type OpCode; //PLUS,MINUS,MUL,DIV,POWER,FUNC,CONST_ID,T
union
{
struct { ExprNode *Left, *Right; }CaseOperater; //二元运算:只有左右孩子的内部节点
struct { ExprNode *Child; FuncPtr MathFuncPtr; }CaseFunc;//函数调用:只有一个孩子的内部节点,还有一个指向对应函数名的指针 MathFuncPtr
double CaseConst; //常数:叶子节点 右值
double *CaseParmPtr; //参数T 左值:存放T的值得地址
}Content;
};
extern void Parser(char *SrcFilePtr); //语法分析器对外接口
#endif #pragma once
#pragma onceScanner.h
#ifndef SCANNER_H
#define SCANNER_H
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <ctype.h> //ctype.h是C标准函数库中的头文件,定义了一批C语言字符分类函数,用于测试字符是否属于特定的字符类别,
//如字母字符、控制字符等等。
#include <stdarg.h>//让函数可以接收可变参数
#include <math.h>
enum Token_Type//记号类别枚举
{
ORIGIN/* 0 */, SCALE/* 1 */, ROT/* 2 */, IS/* 3 */, TO/* 4 */, STEP/* 5 */, DRAW/* 6 */, FOR/* 7 */, FROM/* 8 */,//保留字
T/* 9 */,//参数
SEMICO/* 10 */, L_BRACKET/* 11 */, R_BRACKET/* 12 */, COMMA/* 13 */,//分层符号
PLUS/* 14 */, MINUS/* 15 */, MUL/* 16 */, DIV/* 17 */, POWER/* 18 */,//运算符
FUNC/*19 */,//函数
CONST_ID/* 20 */,//常数
NONTOKEN/* 21 */,//空记号,标记源程序文件的结束
ERRTOKEN/* 22 *///出错记号,标记非法输入
};
typedef double(*MathFuncPtr)(double);//MathFuncPtr代表一个指向返回double值并带有一个double形参的函数的指针的类型
struct Token
{
Token_Type type;//记号类别
char * lexeme;//属性,字符串,指向char类型的指针
double value;//属性,常数的值,double型
double(*FuncPtr)(double);//属性,函数指针,代表一个指向返回double值并带有一个double形参的函数的指针的类型
};
static Token TokenTab[] = //符号表内容
{
{ CONST_ID, (char*)"PI", 3.1415926, NULL },
{ CONST_ID, (char*)"E", 2.71828, NULL },
{ T, (char*)"T", 0.0, NULL },
{ FUNC, (char*)"SIN", 0.0, sin },
{ FUNC, (char*)"COS", 0.0, cos },
{ FUNC, (char*)"TAN", 0.0, tan },
{ FUNC, (char*)"LN", 0.0, log },
{ FUNC, (char*)"EXP", 0.0, exp },
{ FUNC, (char*)"SQRT", 0.0, sqrt },
{ ORIGIN, (char*)"ORIGIN", 0.0, NULL },
{ SCALE, (char*)"SCALE", 0.0, NULL },
{ ROT, (char*)"ROT", 0.0, NULL },
{ IS, (char*)"IS", 0.0, NULL },
{ FOR, (char*)"FOR", 0.0, NULL },
{ FROM, (char*)"FROM", 0.0, NULL },
{ TO, (char*)"TO", 0.0, NULL },
{ STEP, (char*)"STEP", 0.0, NULL },
{ DRAW, (char*)"DRAW", 0.0, NULL },
};
extern unsigned int LineNo;//跟踪记号所在源文件行号
extern int InitScanner(const char *);//初始化词法分析器
extern Token GetToken(void);//获取记号函数
extern void CloseScanner(void);//关闭词法分析器
#endif#pragma once
#pragma onceParser.cpp
#include"parser.h"
//#include"semantic.h"
#include<Windows.h>
#define Tree_trace(x) PrintSyntaxTree(x,1);
#pragma warning(disable: 4996)
#pragma warning(disable: 4703)
double Parameter = 0,
Origin_x = 0, Origin_y = 0,
Scale_x = 1, Scale_y = 1,
Rot_angle = 0;
static Token token;//定义一个记号
//辅助函数声明
static void FetchToken();//调用词法分析器的GetToken,把得到的当前记录保存起来。如果得到的记号是非法输入errtoken,则指出一个语法错误
static void MatchToken(enum Token_Type The_Token);//匹配当前记号
static void SyntaxError(int case_of);//处理语法错误的子程序。根据错误的性质打印相关信息并且终止程序运行。错误性质可以根据传参不同来区分:SyntaxError(1)词法错 SyntaxError(2)语法错
static void ErrMsg(unsigned LineNo, char *descrip, char *string);//打印错误信息
static void PrintSyntaxTree(struct ExprNode *root, int indent);//先序遍历打印语法树
//非终结符递归子程序声明 有2类
//第1类,语法分析,不构造语法树,因此语句的子程序均设计为过程->void类型的函数,非终结符的递归子程序声明
static void Program();//程序
static void Statement();//语句
static void OriginStatement();//Origin语句
static void RotStatement();//Rot语句
static void ScaleStatement();//Scale语句
static void ForStatement();//For语句
//第2类,语法分析+构造语法树,因此表达式均设计为返回值为指向语法树节点的指针的函数。
static struct ExprNode *Expression();//表达式、二元加减运算表达式
static struct ExprNode *Term();//乘除运算表达式
static struct ExprNode *Factor();//一元加减运算表达式
//把项和因子独立开处理解决了加减号与乘除号的优先级问题。在这几个过程的反复调用中,始终传递fsys变量的值,保证可以在出错的情况下跳过出错的符号,使分析过程得以进行下去。
static struct ExprNode *Component();//幂运算表达式
static struct ExprNode *Atom();//原子表达式
//对外接口声明
extern void Parser(char *SrcFilePtr);
//语法树构造函数声明
static struct ExprNode *MakeExprNode(enum Token_Type opcode, ...);
//通过词法分析器接口GetToken获得一个记号
static void FetchToken()
{
token = GetToken();
if (token.type == ERRTOKEN) SyntaxError(1); //如果得到的记号是非法输入errtoken,则指出一个语法错误
}
//匹配当前记号
static void MatchToken(enum Token_Type The_Token)
{
if (token.type != The_Token)
{
SyntaxError(2);//若失败,指出语法错误
}
FetchToken();//若成功,获取下一个
}
//语法错误处理
static void SyntaxError(int case_of)
{
switch (case_of)
{
case 1: ErrMsg(LineNo, (char*)"错误记号 ", token.lexeme);
break;
case 2: ErrMsg(LineNo, (char*)"不是预期记号", token.lexeme);
break;
}
}
//打印错误信息
void ErrMsg(unsigned LineNo, char *descrip, char *string)
{
char msg[256];
memset(msg, 0, 256);
sprintf(msg, "Line No %5d:%s %s !", LineNo, descrip, string);
MessageBoxA(NULL, msg, "error!", MB_OK);
CloseScanner();
exit(1);
}
//先序遍历打印语法树,根-左-右
void PrintSyntaxTree(struct ExprNode *root, int indent)
{
int temp;
for (temp = 1; temp <= indent; temp++) printf("\t");//缩进
switch (root->OpCode)
{
case PLUS: printf("%s\n", "+"); break;
case MINUS: printf("%s\n", "-"); break;
case MUL: printf("%s\n", "*"); break;
case DIV: printf("%s\n", "/"); break;
case POWER: printf("%s\n", "**"); break;
case FUNC: printf("%x\n", root->Content.CaseFunc.MathFuncPtr); break;
case CONST_ID: printf("%f\n", root->Content.CaseConst); break;
case T: printf("%s\n", "T"); break;
default: printf("Error Tree Node !\n"); exit(0);
}
if (root->OpCode == CONST_ID || root->OpCode == T) //叶子节点返回
return;//常数和参数只有叶子节点 常数:右值;参数:左值地址
if (root->OpCode == FUNC)//递归打印一个孩子节点
PrintSyntaxTree(root->Content.CaseFunc.Child, indent + 1);//函数有孩子节点和指向函数名的指针
else//递归打印两个孩子节点
{//二元运算:左右孩子的内部节点
PrintSyntaxTree(root->Content.CaseOperater.Left, indent + 1);
PrintSyntaxTree(root->Content.CaseOperater.Right, indent + 1);
}
}
//绘图语言解释器入口(与主程序的外部接口)
void Parser(char *SrcFilePtr)//语法分析器的入口
{
if (!InitScanner(SrcFilePtr))//初始化词法分析器
{
printf("Open Source File Error !\n"); return;
}
FetchToken();//先获得一个记号
Program();//然后进入Program递归子程序,递归下降分析
CloseScanner();//关闭词法分析器
return;
}
//程序Program的递归子程序
static void Program()
{
while (token.type != NONTOKEN)//记号类型不为空
{
Statement();//程序有多个语句
MatchToken(SEMICO);//直到匹配到分隔符
}
}
//语句Statment的递归子程序
static void Statement()
{
switch (token.type)
{
//罗列四种语句类型,分别分析
case ORIGIN: OriginStatement(); break;
case SCALE: ScaleStatement(); break;
case ROT: RotStatement(); break;
case FOR: ForStatement(); break;
default: SyntaxError(2); //否则报错
}
}
//语句OriginStatement的递归子程序
static void OriginStatement(void)
{
struct ExprNode *tmp;//语法树节点的类型
MatchToken(ORIGIN);
MatchToken(IS);
MatchToken(L_BRACKET);
tmp = Expression(); Tree_trace(tmp);
//Origin_x = GetExprValue(tmp);//获取横坐标点平移距离
//DelExprTree(tmp);//删除一棵树
MatchToken(COMMA);
tmp = Expression(); Tree_trace(tmp);
//Origin_y = GetExprValue(tmp);//获取纵坐标点平移距离
//DelExprTree(tmp);//删除一棵树
MatchToken(R_BRACKET);
}
//语句ScaleStatement的递归子程序
static void ScaleStatement(void)
{
struct ExprNode *tmp;
MatchToken(SCALE);
MatchToken(IS);
MatchToken(L_BRACKET);
tmp = Expression(); Tree_trace(tmp);
//Scale_x = GetExprValue(tmp);//获取横坐标的比例因子
//DelExprTree(tmp);
MatchToken(COMMA);
tmp = Expression(); Tree_trace(tmp);
//Scale_y = GetExprValue(tmp);//获取纵坐标的比例因子
//DelExprTree(tmp);
MatchToken(R_BRACKET);
}
//语句RotStatement的递归子程序
static void RotStatement(void)
{
struct ExprNode *tmp;
MatchToken(ROT);
MatchToken(IS);
tmp = Expression(); Tree_trace(tmp);
//Rot_angle = GetExprValue(tmp);//获得旋转角度
//DelExprTree(tmp);
}
//语句ForStatement的递归子程序
//对右部文法符号的展开->遇到终结符号直接匹配,遇到非终结符就调用相应子程序
//ForStatement中唯一的非终结符是Expression,他出现在5个不同位置,分别代表循环的起始、终止、步长、横坐标、纵坐标,需要5个树节点指针保存这5棵语法树
static void ForStatement(void)
{
//eg:for T from 0 to 2*pi step pi/50 draw (t, -sin(t));
double Start, End, Step;//绘图起点、终点、步长
struct ExprNode *start_ptr, *end_ptr, *step_ptr, *x_ptr, *y_ptr;
MatchToken(FOR);
MatchToken(T);
MatchToken(FROM);//eg:for T from
start_ptr = Expression(); Tree_trace(start_ptr);//获得参数起点表达式的语法树
//Start = GetExprValue(start_ptr);//计算参数起点表达式的值
//DelExprTree(start_ptr);//释放参数起点语法树所占空间
MatchToken(TO);
end_ptr = Expression(); Tree_trace(end_ptr);//构造参数终点表达式语法树
//End = GetExprValue(end_ptr);//计算参数终点表达式的值
//DelExprTree(end_ptr);//释放参数终点语法树所占空间
MatchToken(STEP);
step_ptr = Expression(); Tree_trace(step_ptr);//构造参数步长表达式语法树
//Step = GetExprValue(step_ptr);//计算参数步长表达式的值
//DelExprTree(step_ptr);//释放参数步长语法树所占空间
MatchToken(DRAW);
MatchToken(L_BRACKET);
x_ptr = Expression(); Tree_trace(x_ptr);
MatchToken(COMMA);
y_ptr = Expression();Tree_trace(y_ptr);
MatchToken(R_BRACKET);
//DrawLoop(Start, End, Step, x_ptr, y_ptr); //绘制图形
//DelExprTree(x_ptr);//释放横坐标语法树所占空间
//DelExprTree(y_ptr);//释放纵坐标语法树所占空间
}
//(二元加减运算)表达式Expression的递归子程序,与上边不太相同的是,表达式需要为其构造语法树
//把函数设计为语法树节点的指针,在函数内引进2个语法树节点的指针变量,分别作为Expression左右操作数(Term)的语法树节点指针
//表达式应该是由正负号或无符号开头、由若干个项以加减号连接而成。
static struct ExprNode *Expression()//展开右部,并且构造语法树
{
struct ExprNode *left, *right;//左右子树节点指针
Token_Type token_tmp;//当前记号
left = Term();//分析左操作数得到其语法树,左操作数是一个乘除运算表达式
while (token.type == PLUS || token.type == MINUS)
{
token_tmp = token.type;//当前记号是加/减
MatchToken(token_tmp);//匹配记号
right = Term();//分析右操作数得到其语法树,右操作数是一个乘除运算表达式
left = MakeExprNode(token_tmp, left, right);//构造运算的语法树,结果为左子树
}
return left;//返回的是当前记号节点
}
//乘除运算表达式Term的递归子程序
//项是由若干个因子以乘除号连接而成
static struct ExprNode *Term()
{
struct ExprNode *left, *right;
Token_Type token_tmp;
left = Factor();
while (token.type == MUL || token.type == DIV)
{
token_tmp = token.type;
MatchToken(token_tmp);
right = Factor();
left = MakeExprNode(token_tmp, left, right);
}
return left;
}
//一元加减运算Factor的递归子程序
//因子则可能是一个标识符或一个数字,或是一个以括号括起来的子表达式
static struct ExprNode *Factor()
{
struct ExprNode *left, *right;
if (token.type == PLUS)//匹配一元加运算
{
MatchToken(PLUS);
right = Factor();
}
else if (token.type == MINUS)//表达式退化为仅有右操作数的表达式
{
MatchToken(MINUS);
right = Factor();
left = new ExprNode;
left->OpCode = CONST_ID;
left->Content.CaseConst = 0.0;
right = MakeExprNode(MINUS, left, right);
}
else right = Component();//匹配非终结符Component
return right;
}
//幂运算表达式Component的递归子程序
static struct ExprNode *Component()//右结合
{
struct ExprNode *left, *right;
left = Atom();
if (token.type == POWER)
{
MatchToken(POWER);
right = Component();//递归调用Component以实现POWER的右结合
left = MakeExprNode(POWER, left, right);
}
return left;
}
//原子表达式Atom的递归子程序,包括分隔符 函数 常数 参数
static struct ExprNode *Atom()
{
struct Token t = token;
struct ExprNode *address, *tmp;
switch (token.type)
{
case CONST_ID:
MatchToken(CONST_ID);
address = MakeExprNode(CONST_ID, t.value);
break;
case T:
MatchToken(T);
address = MakeExprNode(T);
break;
case FUNC:
MatchToken(FUNC);
MatchToken(L_BRACKET);
tmp = Expression(); Tree_trace(tmp);
address = MakeExprNode(FUNC, t.FuncPtr, tmp);
MatchToken(R_BRACKET);
break;
case L_BRACKET:
MatchToken(L_BRACKET);
address = Expression(); Tree_trace(address);
MatchToken(R_BRACKET);
break;
default:
SyntaxError(2);
}
return address;
}
//生成语法树的一个节点,接收可变参数列表
static struct ExprNode * MakeExprNode(enum Token_Type opcode, ...)//注意这个函数是一个可变参数的函数
{
struct ExprNode *ExprPtr = new(struct ExprNode);//为新节点开辟空间
ExprPtr->OpCode = opcode;//向节点写入记号类别
va_list ArgPtr;//指向可变函数的参数的指针
va_start(ArgPtr, opcode);//初始化va_list变量,第一个参数也就是固定参数为opcode
switch (opcode)//根据记号的类别构造不同的节点
{
case CONST_ID://常数节点
ExprPtr->Content.CaseConst = (double)va_arg(ArgPtr, double);//返回可变参数,可变参数类型是常数
break;
case T://参数T节点
ExprPtr->Content.CaseParmPtr = &Parameter;//返回可变参数,可变参数类型是参数T
break;
case FUNC://函数调用节点
ExprPtr->Content.CaseFunc.MathFuncPtr = (FuncPtr)va_arg(ArgPtr, FuncPtr);//可变参数类型是对应函数的指针
ExprPtr->Content.CaseFunc.Child = (struct ExprNode *)va_arg(ArgPtr, struct ExprNode *);//可变参数类型是节点
break;
default://二元运算节点
ExprPtr->Content.CaseOperater.Left = (struct ExprNode *)va_arg(ArgPtr, struct ExprNode *);//可变参数类型是节点
ExprPtr->Content.CaseOperater.Right = (struct ExprNode *)va_arg(ArgPtr, struct ExprNode *);//同上
break;
}
va_end(ArgPtr);//结束可变参数的获取
return ExprPtr;
}Scanner.cpp
#include "scanner.h"
#define TOKEN_LEN 100//记号最大长度
#pragma warning(disable: 4996)
unsigned int LineNo;//源文件行号
static FILE *InFile;//输入文件流
static char TokenBuffer[TOKEN_LEN];//记号字符缓冲
//初始化词法分析器
extern int InitScanner(const char *FileName)
{
LineNo = 1;//行号
InFile = fopen(FileName, "r");//只读形式打开文件
if (InFile != NULL) return 1;//打开成功
else return 0;//打开失败
}
//关闭词法分析器
extern void CloseScanner(void)
{
if (InFile != NULL)
fclose(InFile);//关闭文件
}
//从输入源程序(流)读字符
static char GetChar(void)
{
char Char = getc(InFile);//逐个字符读
return toupper(Char);//全部转换为大写,然后return
}
//将预读字符退回源程序(流)
static void BackChar(char Char)
{
if (Char != EOF)
ungetc(Char, InFile);
}
//加入字符到记号缓冲区
static void AddCharTokenString(char Char)
{
int TokenLength = strlen(TokenBuffer);
if (TokenLength + 1 >= sizeof(TokenBuffer)) return;//数组越界
TokenBuffer[TokenLength] = Char;//写入字符到缓冲区
TokenBuffer[TokenLength + 1] = '\0';//加入字符串结束标志“\0”
}
//请空记号缓冲区
static void EmptyTokenString()
{
memset(TokenBuffer, 0, TOKEN_LEN);
}
//判断记号是否在记号表中
static Token JudgeKeyToken(const char *IDString)
{
int loop;
//sizeof(TokenTab)L:表示这个数组一共占了多少字节数;sizeof(TokenTab[0]):表示一个元素所占的字节数,两者相除,表述数组中一共有多少个元素
for (loop = 0; loop < sizeof(TokenTab) / sizeof(TokenTab[0]); loop++)
{ //遍历TokenTab表
if (strcmp(TokenTab[loop].lexeme, IDString) == 0)
return TokenTab[loop];//判断在字符表中就返回该记号
}
Token errortoken;
memset(&errortoken, 0, sizeof(Token));//先将errortoken置空
errortoken.type = ERRTOKEN;//然后填入出错记号
return errortoken;//返回出错记号
}
//获得一个记号
extern Token GetToken(void)
{
Token token;
char Char;
memset(&token, 0, sizeof(Token));//token置空
EmptyTokenString();//清空记号缓冲区
token.lexeme = TokenBuffer;
for (;;)//此循环用来过滤掉源程序中的空格、TAB、回车等分隔符,文件结束返回空记号
{
Char = GetChar();//从源程序读字符
if (Char == EOF)//读出错
{
token.type = NONTOKEN;
return token;
}
if (Char == '\n')
LineNo++;//行号+1
if (!isspace(Char))//遇到空格该记号肯定已经完成,退出循环
break;
}
AddCharTokenString(Char);//如果不是上面的那些分隔符,就先加入缓冲区
if (isalpha(Char))//如果是英文字母,一定是函数、关键字、PI、E等
{
for (;;)
{
Char = GetChar();
if (isalnum(Char))//如果是字母或数字
AddCharTokenString(Char);//加入缓冲区
else break;
}
BackChar(Char);//退回缓冲区
token = JudgeKeyToken(TokenBuffer);//判断是否在记号表中
token.lexeme = TokenBuffer;
return token;
}
else if (isdigit(Char))//如果是数字,一定是常量
{
for (;;)
{
Char = GetChar();
if (isdigit(Char))
AddCharTokenString(Char);
else break;
}
if (Char == '.')
{
AddCharTokenString(Char);
for (;;)
{
Char = GetChar();
if (isdigit(Char))
AddCharTokenString(Char);
else break;
}
}
BackChar(Char);
token.type = CONST_ID;
token.value = atof(TokenBuffer);
return token;
}
else//如果是其他符号
{
switch (Char)
{
case ';': token.type = SEMICO; break;
case '(': token.type = L_BRACKET; break;
case ')': token.type = R_BRACKET; break;
case ',': token.type = COMMA; break;
case '+': token.type = PLUS; break;
case '-':
Char = GetChar();
if (Char == '-')
{
while (Char != '\n' && Char != EOF) Char = GetChar();
BackChar(Char);
return GetToken();
}
else
{
BackChar(Char);
token.type = MINUS;
break;
}
case '/':
Char = GetChar();
if (Char == '/')
{
while (Char != '\n' && Char != EOF) Char = GetChar();
BackChar(Char);
return GetToken();
}
else
{
BackChar(Char);
token.type = DIV;
break;
}
case '*':
Char = GetChar();
if (Char == '*')
{
token.type = POWER;
break;
}
else
{
BackChar(Char);
token.type = MUL;
break;
}
default:token.type = ERRTOKEN; break;
}
}
return token;
}test_parser.cpp
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include"parser.h"
#pragma warning(disable:4996)
extern void Parser( char *SrcFilePtr);
int main(int argc, char *argv[])
{
char*p;
p = (char*)malloc(20 * sizeof(char));
memset(p, 0, sizeof(char) * 20);
strcpy(p, "test_parser.txt");
Parser(p);
free(p);
system("pause");
}3、语义分析器及绘图
测试文本:
test2.txt
--------------- 图形1:
origin is (20, 200); -- 设置原点的偏移量
rot is 0; -- 不旋转
scale is (40, 40); -- 设置比例
for T from 0 to 2*pi step pi/50 draw (t, -sin(t)); -- 画T的轨迹
origin is (20, 240); -- 下移40单位
for T from 0 to 2*pi step pi/50 draw (t, -sin(t)); -- 画T的轨迹
origin is (20, 280); -- 再下移40单位
for T from 0 to 2*pi step pi/50 draw (t, -sin(t)); -- 画T的轨迹
--------------- 图形2:
origin is (380, 240); -- 右移
scale is (80, 80/3); -- y方向压缩为三分之一
rot is pi/2+0*pi/3 ; -- 旋转初值设置
for T from -pi to pi step pi/50 draw (cos(t), sin(t)); -- 画T的轨迹
rot is pi/2+2*pi/3; -- 旋转2/3*pi
for T from -pi to pi step pi/50 draw (cos(t), sin(t)); -- 画T的轨迹
rot is pi/2-2*pi/3; -- 再旋转2/3*pi
for T from -pi to pi step pi/50 draw (cos(t), sin(t)); -- 画T的轨迹
--------------- 图形3:
origin is(580, 240); -- 再右移
scale is (80, 80); -- 恢复原比例
rot is 0; -- 不旋转
for t from 0 to 2*pi step pi/50 draw(cos(t),sin(t)); -- 画T的轨迹
for t from 0 to Pi*20 step Pi/50 draw -- 画T的轨迹
((1-1/(10/7))*Cos(T)+1/(10/7)*Cos(-T*((10/7)-1)),
(1-1/(10/7))*Sin(T)+1/(10/7)*Sin(-T*((10/7)-1)));Semantic.h
#include<windows.h>
#include<wingdi.h>
//“VC_Compiler”是用windows自带图形库实现的词法分析器,程序结果输出函数绘图语言解释器绘出的图像
#include"parser.h"
#define red RGB(255,0,0)//红色
#define black RGB(0,0,0)//黑色
//外部函数声明
extern void DrawPixel(unsigned long x, unsigned long y);//绘制一个点
extern double GetExprValue(struct ExprNode * root);//获得表达式的值
extern void DrawLoop(double Start,
double End,
double Step,
struct ExprNode *HorPtr,
struct ExprNode *VerPtr);//图形绘制
extern void DelExprTree(struct ExprNode *root);//删除一棵树#pragma once
#pragma onceScanner.h
#ifndef SCANNER_H
#define SCANNER_H
#include <string.h>
#include <stdio.h>
#include <stdlib.h>
#include <ctype.h> //ctype.h是C标准函数库中的头文件,定义了一批C语言字符分类函数,用于测试字符是否属于特定的字符类别,
//如字母字符、控制字符等等。
#include <stdarg.h>//让函数可以接收可变参数
#include <math.h>
enum Token_Type//记号类别枚举
{
ORIGIN/* 0 */, SCALE/* 1 */, ROT/* 2 */, IS/* 3 */, TO/* 4 */, STEP/* 5 */, DRAW/* 6 */, FOR/* 7 */, FROM/* 8 */,//保留字
T/* 9 */,//参数
SEMICO/* 10 */, L_BRACKET/* 11 */, R_BRACKET/* 12 */, COMMA/* 13 */,//分层符号
PLUS/* 14 */, MINUS/* 15 */, MUL/* 16 */, DIV/* 17 */, POWER/* 18 */,//运算符
FUNC/*19 */,//函数
CONST_ID/* 20 */,//常数
NONTOKEN/* 21 */,//空记号,标记源程序文件的结束
ERRTOKEN/* 22 *///出错记号,标记非法输入
};
typedef double(*MathFuncPtr)(double);//MathFuncPtr代表一个指向返回double值并带有一个double形参的函数的指针的类型
struct Token
{
Token_Type type;//记号类别
char * lexeme;//属性,字符串,指向char类型的指针
double value;//属性,常数的值,double型
double(*FuncPtr)(double);//属性,函数指针,代表一个指向返回double值并带有一个double形参的函数的指针的类型
};
static Token TokenTab[] = //符号表内容
{
{ CONST_ID, (char*)"PI", 3.1415926, NULL },
{ CONST_ID, (char*)"E", 2.71828, NULL },
{ T, (char*)"T", 0.0, NULL },
{ FUNC, (char*)"SIN", 0.0, sin },
{ FUNC, (char*)"COS", 0.0, cos },
{ FUNC, (char*)"TAN", 0.0, tan },
{ FUNC, (char*)"LN", 0.0, log },
{ FUNC, (char*)"EXP", 0.0, exp },
{ FUNC, (char*)"SQRT", 0.0, sqrt },
{ ORIGIN, (char*)"ORIGIN", 0.0, NULL },
{ SCALE, (char*)"SCALE", 0.0, NULL },
{ ROT, (char*)"ROT", 0.0, NULL },
{ IS, (char*)"IS", 0.0, NULL },
{ FOR, (char*)"FOR", 0.0, NULL },
{ FROM, (char*)"FROM", 0.0, NULL },
{ TO, (char*)"TO", 0.0, NULL },
{ STEP, (char*)"STEP", 0.0, NULL },
{ DRAW, (char*)"DRAW", 0.0, NULL },
};
extern unsigned int LineNo;//跟踪记号所在源文件行号
extern int InitScanner(const char *);//初始化词法分析器
extern Token GetToken(void);//获取记号函数
extern void CloseScanner(void);//关闭词法分析器
#endif#pragma once
#pragma onceParser.h
#ifndef PARSER_H
#define PARSER_H
#include"scanner.h"
typedef double(*FuncPtr)(double);
struct ExprNode //语法树节点类型
{
enum Token_Type OpCode; //PLUS,MINUS,MUL,DIV,POWER,FUNC,CONST_ID,T
union
{
struct { ExprNode *Left, *Right; }CaseOperater; //二元运算:只有左右孩子的内部节点
struct { ExprNode *Child; FuncPtr MathFuncPtr; }CaseFunc;//函数调用:只有一个孩子的内部节点,还有一个指向对应函数名的指针 MathFuncPtr
double CaseConst; //常数:叶子节点 右值
double *CaseParmPtr; //参数T 左值:存放T的值得地址
}Content;
};
extern void Parser(char *SrcFilePtr); //语法分析器对外接口
#endif #pragma once
#pragma onceScanner.cpp
#include "scanner.h"
#define TOKEN_LEN 100//记号最大长度
#pragma warning(disable: 4996)
unsigned int LineNo;//源文件行号
static FILE *InFile;//输入文件流
static char TokenBuffer[TOKEN_LEN];//记号字符缓冲
//初始化词法分析器
extern int InitScanner(const char *FileName)
{
LineNo = 1;//行号
InFile = fopen(FileName, "r");//只读形式打开文件
if (InFile != NULL) return 1;//打开成功
else return 0;//打开失败
}
//关闭词法分析器
extern void CloseScanner(void)
{
if (InFile != NULL)
fclose(InFile);//关闭文件
}
//从输入源程序(流)读字符
static char GetChar(void)
{
char Char = getc(InFile);//逐个字符读
return toupper(Char);//全部转换为大写,然后return
}
//将预读字符退回源程序(流)
static void BackChar(char Char)
{
if (Char != EOF)
ungetc(Char, InFile);
}
//加入字符到记号缓冲区
static void AddCharTokenString(char Char)
{
int TokenLength = strlen(TokenBuffer);
if (TokenLength + 1 >= sizeof(TokenBuffer)) return;//数组越界
TokenBuffer[TokenLength] = Char;//写入字符到缓冲区
TokenBuffer[TokenLength + 1] = '\0';//加入字符串结束标志“\0”
}
//请空记号缓冲区
static void EmptyTokenString()
{
memset(TokenBuffer, 0, TOKEN_LEN);
}
//判断记号是否在记号表中
static Token JudgeKeyToken(const char *IDString)
{
int loop;
//sizeof(TokenTab)L:表示这个数组一共占了多少字节数;sizeof(TokenTab[0]):表示一个元素所占的字节数,两者相除,表述数组中一共有多少个元素
for (loop = 0; loop < sizeof(TokenTab) / sizeof(TokenTab[0]); loop++)
{ //遍历TokenTab表
if (strcmp(TokenTab[loop].lexeme, IDString) == 0)
return TokenTab[loop];//判断在字符表中就返回该记号
}
Token errortoken;
memset(&errortoken, 0, sizeof(Token));//先将errortoken置空
errortoken.type = ERRTOKEN;//然后填入出错记号
return errortoken;//返回出错记号
}
//获得一个记号
extern Token GetToken(void)
{
Token token;
char Char;
memset(&token, 0, sizeof(Token));//token置空
EmptyTokenString();//清空记号缓冲区
token.lexeme = TokenBuffer;
for (;;)//此循环用来过滤掉源程序中的空格、TAB、回车等分隔符,文件结束返回空记号
{
Char = GetChar();//从源程序读字符
if (Char == EOF)//读出错
{
token.type = NONTOKEN;
return token;
}
if (Char == '\n')
LineNo++;//行号+1
if (!isspace(Char))//遇到空格该记号肯定已经完成,退出循环
break;
}
AddCharTokenString(Char);//如果不是上面的那些分隔符,就先加入缓冲区
if (isalpha(Char))//如果是英文字母,一定是函数、关键字、PI、E等
{
for (;;)
{
Char = GetChar();
if (isalnum(Char))//如果是字母或数字
AddCharTokenString(Char);//加入缓冲区
else break;
}
BackChar(Char);//退回缓冲区
token = JudgeKeyToken(TokenBuffer);//判断是否在记号表中
token.lexeme = TokenBuffer;
return token;
}
else if (isdigit(Char))//如果是数字,一定是常量
{
for (;;)
{
Char = GetChar();
if (isdigit(Char))
AddCharTokenString(Char);
else break;
}
if (Char == '.')
{
AddCharTokenString(Char);
for (;;)
{
Char = GetChar();
if (isdigit(Char))
AddCharTokenString(Char);
else break;
}
}
BackChar(Char);
token.type = CONST_ID;
token.value = atof(TokenBuffer);
return token;
}
else//如果是其他符号
{
switch (Char)
{
case ';': token.type = SEMICO; break;
case '(': token.type = L_BRACKET; break;
case ')': token.type = R_BRACKET; break;
case ',': token.type = COMMA; break;
case '+': token.type = PLUS; break;
case '-':
Char = GetChar();
if (Char == '-')
{
while (Char != '\n' && Char != EOF) Char = GetChar();
BackChar(Char);
return GetToken();
}
else
{
BackChar(Char);
token.type = MINUS;
break;
}
case '/':
Char = GetChar();
if (Char == '/')
{
while (Char != '\n' && Char != EOF) Char = GetChar();
BackChar(Char);
return GetToken();
}
else
{
BackChar(Char);
token.type = DIV;
break;
}
case '*':
Char = GetChar();
if (Char == '*')
{
token.type = POWER;
break;
}
else
{
BackChar(Char);
token.type = MUL;
break;
}
default:token.type = ERRTOKEN; break;
}
}
return token;
}Parser.cpp
#include"parser.h"
#include"semantic.h"
//#define Tree_trace(x) PrintSyntaxTree(x,1);
#pragma warning(disable: 4996)
#pragma warning(disable: 4703)
double Parameter = 0,
Origin_x = 0, Origin_y = 0,
Scale_x = 1, Scale_y = 1,
Rot_angle = 0;
static Token token;//定义一个记号
//辅助函数声明
static void FetchToken();//调用词法分析器的GetToken,把得到的当前记录保存起来。如果得到的记号是非法输入errtoken,则指出一个语法错误
static void MatchToken(enum Token_Type The_Token);//匹配当前记号
static void SyntaxError(int case_of);//处理语法错误的子程序。根据错误的性质打印相关信息并且终止程序运行。错误性质可以根据传参不同来区分:SyntaxError(1)词法错 SyntaxError(2)语法错
static void ErrMsg(unsigned LineNo, char *descrip, char *string);//打印错误信息
static void PrintSyntaxTree(struct ExprNode *root, int indent);//先序遍历打印语法树
//非终结符递归子程序声明 有2类
//第1类,语法分析,不构造语法树,因此语句的子程序均设计为过程->void类型的函数,非终结符的递归子程序声明
static void Program();//程序
static void Statement();//语句
static void OriginStatement();//Origin语句
static void RotStatement();//Rot语句
static void ScaleStatement();//Scale语句
static void ForStatement();//For语句
//第2类,语法分析+构造语法树,因此表达式均设计为返回值为指向语法树节点的指针的函数。
static struct ExprNode *Expression();//表达式、二元加减运算表达式
static struct ExprNode *Term();//乘除运算表达式
static struct ExprNode *Factor();//一元加减运算表达式
//把项和因子独立开处理解决了加减号与乘除号的优先级问题。在这几个过程的反复调用中,始终传递fsys变量的值,保证可以在出错的情况下跳过出错的符号,使分析过程得以进行下去。
static struct ExprNode *Component();//幂运算表达式
static struct ExprNode *Atom();//原子表达式
//对外接口声明
extern void Parser(char *SrcFilePtr);
//语法树构造函数声明
static struct ExprNode *MakeExprNode(enum Token_Type opcode, ...);
//通过词法分析器接口GetToken获得一个记号
static void FetchToken()
{
token = GetToken();
if (token.type == ERRTOKEN) SyntaxError(1); //如果得到的记号是非法输入errtoken,则指出一个语法错误
}
//匹配当前记号
static void MatchToken(enum Token_Type The_Token)
{
if (token.type != The_Token)
{
SyntaxError(2);//若失败,指出语法错误
}
FetchToken();//若成功,获取下一个
}
//语法错误处理
static void SyntaxError(int case_of)
{
switch (case_of)
{
case 1: ErrMsg(LineNo, (char*)"错误记号 ", token.lexeme);
break;
case 2: ErrMsg(LineNo, (char*)"不是预期记号", token.lexeme);
break;
}
}
//打印错误信息
void ErrMsg(unsigned LineNo, char *descrip, char *string)
{
char msg[256];
memset(msg, 0, 256);
sprintf(msg, "Line No %5d:%s %s !", LineNo, descrip, string);
MessageBoxA(NULL, msg, "error!", MB_OK);
CloseScanner();
exit(1);
}
//先序遍历打印语法树,根-左-右
void PrintSyntaxTree(struct ExprNode *root, int indent)
{
int temp;
for (temp = 1; temp <= indent; temp++) printf("\t");//缩进
switch (root->OpCode)
{
case PLUS: printf("%s\n", "+"); break;
case MINUS: printf("%s\n", "-"); break;
case MUL: printf("%s\n", "*"); break;
case DIV: printf("%s\n", "/"); break;
case POWER: printf("%s\n", "**"); break;
case FUNC: printf("%x\n", root->Content.CaseFunc.MathFuncPtr); break;
case CONST_ID: printf("%f\n", root->Content.CaseConst); break;
case T: printf("%s\n", "T"); break;
default: printf("Error Tree Node !\n"); exit(0);
}
if (root->OpCode == CONST_ID || root->OpCode == T) //叶子节点返回
return;//常数和参数只有叶子节点 常数:右值;参数:左值地址
if (root->OpCode == FUNC)//递归打印一个孩子节点
PrintSyntaxTree(root->Content.CaseFunc.Child, indent + 1);//函数有孩子节点和指向函数名的指针
else//递归打印两个孩子节点
{//二元运算:左右孩子的内部节点
PrintSyntaxTree(root->Content.CaseOperater.Left, indent + 1);
PrintSyntaxTree(root->Content.CaseOperater.Right, indent + 1);
}
}
//绘图语言解释器入口(与主程序的外部接口)
void Parser(char *SrcFilePtr)//语法分析器的入口
{
if (!InitScanner(SrcFilePtr))//初始化词法分析器
{
printf("Open Source File Error !\n"); return;
}
FetchToken();//先获得一个记号
Program();//然后进入Program递归子程序,递归下降分析
CloseScanner();//关闭词法分析器
return;
}
//程序Program的递归子程序
static void Program()
{
while (token.type != NONTOKEN)//记号类型不为空
{
Statement();//程序有多个语句
MatchToken(SEMICO);//直到匹配到分隔符
}
}
//语句Statment的递归子程序
static void Statement()
{
switch (token.type)
{
//罗列四种语句类型,分别分析
case ORIGIN: OriginStatement(); break;
case SCALE: ScaleStatement(); break;
case ROT: RotStatement(); break;
case FOR: ForStatement(); break;
default: SyntaxError(2); //否则报错
}
}
//语句OriginStatement的递归子程序
static void OriginStatement(void)
{
struct ExprNode *tmp;//语法树节点的类型
MatchToken(ORIGIN);
MatchToken(IS);
MatchToken(L_BRACKET);
tmp = Expression(); //Tree_trace(tmp);
Origin_x = GetExprValue(tmp);//获取横坐标点平移距离
DelExprTree(tmp);//删除一棵树
MatchToken(COMMA);
tmp = Expression(); //Tree_trace(tmp);
Origin_y = GetExprValue(tmp);//获取纵坐标点平移距离
DelExprTree(tmp);//删除一棵树
MatchToken(R_BRACKET);
}
//语句ScaleStatement的递归子程序
static void ScaleStatement(void)
{
struct ExprNode *tmp;
MatchToken(SCALE);
MatchToken(IS);
MatchToken(L_BRACKET);
tmp = Expression(); //Tree_trace(tmp);
Scale_x = GetExprValue(tmp);//获取横坐标的比例因子
DelExprTree(tmp);
MatchToken(COMMA);
tmp = Expression(); //Tree_trace(tmp);
Scale_y = GetExprValue(tmp);//获取纵坐标的比例因子
DelExprTree(tmp);
MatchToken(R_BRACKET);
}
//语句RotStatement的递归子程序
static void RotStatement(void)
{
struct ExprNode *tmp;
MatchToken(ROT);
MatchToken(IS);
tmp = Expression(); //Tree_trace(tmp);
Rot_angle = GetExprValue(tmp);//获得旋转角度
DelExprTree(tmp);
}
//语句ForStatement的递归子程序
//对右部文法符号的展开->遇到终结符号直接匹配,遇到非终结符就调用相应子程序
//ForStatement中唯一的非终结符是Expression,他出现在5个不同位置,分别代表循环的起始、终止、步长、横坐标、纵坐标,需要5个树节点指针保存这5棵语法树
static void ForStatement(void)
{
//eg:for T from 0 to 2*pi step pi/50 draw (t, -sin(t));
double Start, End, Step;//绘图起点、终点、步长
struct ExprNode *start_ptr, *end_ptr, *step_ptr, *x_ptr, *y_ptr;
MatchToken(FOR);
MatchToken(T);
MatchToken(FROM);//eg:for T from
start_ptr = Expression(); //Tree_trace(start_ptr);//获得参数起点表达式的语法树
Start = GetExprValue(start_ptr);//计算参数起点表达式的值
DelExprTree(start_ptr);//释放参数起点语法树所占空间
MatchToken(TO);
end_ptr = Expression(); //Tree_trace(end_ptr);//构造参数终点表达式语法树
End = GetExprValue(end_ptr);//计算参数终点表达式的值
DelExprTree(end_ptr);//释放参数终点语法树所占空间
MatchToken(STEP);
step_ptr = Expression(); //Tree_trace(step_ptr);//构造参数步长表达式语法树
Step = GetExprValue(step_ptr);//计算参数步长表达式的值
DelExprTree(step_ptr);//释放参数步长语法树所占空间
MatchToken(DRAW);
MatchToken(L_BRACKET);
x_ptr = Expression(); //Tree_trace(x_ptr);
MatchToken(COMMA);
y_ptr = Expression();//Tree_trace(y_ptr);
MatchToken(R_BRACKET);
DrawLoop(Start, End, Step, x_ptr, y_ptr); //绘制图形
DelExprTree(x_ptr);//释放横坐标语法树所占空间
DelExprTree(y_ptr);//释放纵坐标语法树所占空间
}
//(二元加减运算)表达式Expression的递归子程序,与上边不太相同的是,表达式需要为其构造语法树
//把函数设计为语法树节点的指针,在函数内引进2个语法树节点的指针变量,分别作为Expression左右操作数(Term)的语法树节点指针
//表达式应该是由正负号或无符号开头、由若干个项以加减号连接而成。
static struct ExprNode *Expression()//展开右部,并且构造语法树
{
struct ExprNode *left, *right;//左右子树节点指针
Token_Type token_tmp;//当前记号
left = Term();//分析左操作数得到其语法树,左操作数是一个乘除运算表达式
while (token.type == PLUS || token.type == MINUS)
{
token_tmp = token.type;//当前记号是加/减
MatchToken(token_tmp);//匹配记号
right = Term();//分析右操作数得到其语法树,右操作数是一个乘除运算表达式
left = MakeExprNode(token_tmp, left, right);//构造运算的语法树,结果为左子树
}
return left;//返回的是当前记号节点
}
//乘除运算表达式Term的递归子程序
//项是由若干个因子以乘除号连接而成
static struct ExprNode *Term()
{
struct ExprNode *left, *right;
Token_Type token_tmp;
left = Factor();
while (token.type == MUL || token.type == DIV)
{
token_tmp = token.type;
MatchToken(token_tmp);
right = Factor();
left = MakeExprNode(token_tmp, left, right);
}
return left;
}
//一元加减运算Factor的递归子程序
//因子则可能是一个标识符或一个数字,或是一个以括号括起来的子表达式
static struct ExprNode *Factor()
{
struct ExprNode *left, *right;
if (token.type == PLUS)//匹配一元加运算
{
MatchToken(PLUS);
right = Factor();
}
else if (token.type == MINUS)//表达式退化为仅有右操作数的表达式
{
MatchToken(MINUS);
right = Factor();
left = new ExprNode;
left->OpCode = CONST_ID;
left->Content.CaseConst = 0.0;
right = MakeExprNode(MINUS, left, right);
}
else right = Component();//匹配非终结符Component
return right;
}
//幂运算表达式Component的递归子程序
static struct ExprNode *Component()//右结合
{
struct ExprNode *left, *right;
left = Atom();
if (token.type == POWER)
{
MatchToken(POWER);
right = Component();//递归调用Component以实现POWER的右结合
left = MakeExprNode(POWER, left, right);
}
return left;
}
//原子表达式Atom的递归子程序,包括分隔符 函数 常数 参数
static struct ExprNode *Atom()
{
struct Token t = token;
struct ExprNode *address, *tmp;
switch (token.type)
{
case CONST_ID:
MatchToken(CONST_ID);
address = MakeExprNode(CONST_ID, t.value);
break;
case T:
MatchToken(T);
address = MakeExprNode(T);
break;
case FUNC:
MatchToken(FUNC);
MatchToken(L_BRACKET);
tmp = Expression(); //Tree_trace(tmp);
address = MakeExprNode(FUNC, t.FuncPtr, tmp);
MatchToken(R_BRACKET);
break;
case L_BRACKET:
MatchToken(L_BRACKET);
address = Expression(); // Tree_trace(address);
MatchToken(R_BRACKET);
break;
default:
SyntaxError(2);
}
return address;
}
//生成语法树的一个节点,接收可变参数列表
static struct ExprNode * MakeExprNode(enum Token_Type opcode, ...)//注意这个函数是一个可变参数的函数
{
struct ExprNode *ExprPtr = new(struct ExprNode);//为新节点开辟空间
ExprPtr->OpCode = opcode;//向节点写入记号类别
va_list ArgPtr;//指向可变函数的参数的指针
va_start(ArgPtr, opcode);//初始化va_list变量,第一个参数也就是固定参数为opcode
switch (opcode)//根据记号的类别构造不同的节点
{
case CONST_ID://常数节点
ExprPtr->Content.CaseConst = (double)va_arg(ArgPtr, double);//返回可变参数,可变参数类型是常数
break;
case T://参数T节点
ExprPtr->Content.CaseParmPtr = &Parameter;//返回可变参数,可变参数类型是参数T
break;
case FUNC://函数调用节点
ExprPtr->Content.CaseFunc.MathFuncPtr = (FuncPtr)va_arg(ArgPtr, FuncPtr);//可变参数类型是对应函数的指针
ExprPtr->Content.CaseFunc.Child = (struct ExprNode *)va_arg(ArgPtr, struct ExprNode *);//可变参数类型是节点
break;
default://二元运算节点
ExprPtr->Content.CaseOperater.Left = (struct ExprNode *)va_arg(ArgPtr, struct ExprNode *);//可变参数类型是节点
ExprPtr->Content.CaseOperater.Right = (struct ExprNode *)va_arg(ArgPtr, struct ExprNode *);//同上
break;
}
va_end(ArgPtr);//结束可变参数的获取
return ExprPtr;
}Semantic.cpp
#include "semantic.h"
#include<windef.h>
HDC hDC;
extern double
Parameter,//参数T的存储空间:记录t每次加一点的变化 在语法分析中声明的
Origin_x, Origin_y,//横纵坐标平移距离
Scale_x, Scale_y,//横纵比例因子
Rot_angle;//旋转角度
double GetExprValue(struct ExprNode * root);//获得表达式的值
void DrawPixel(unsigned long x, unsigned long y);//绘制一个点
void DrawLoop(double Start,
double End,
double Step,
struct ExprNode *HorPtr,
struct ExprNode *VerPtr);//图形绘制
void DelExprTree(struct ExprNode *root);//删除一棵树
static void Errmsg(char *string);//出错处理
static void CalcCoord(struct ExprNode *Hor_Exp,
struct ExprNode *Ver_Exp,
double &Hor_x,
double &Ver_y);//计算点的坐标
//----------出错处理
void Errmsg(char *string) { exit(1); }
//----------计算被绘制点的坐标
static void CalcCoord(struct ExprNode *Hor_Exp,//横坐标表达式语法树的根节点
struct ExprNode * Ver_Exp,//纵坐标表达式语法树的根节点
double &Hor_x,//点横坐标值,起返回值的作用
double &Ver_y)//点纵坐标值,起返回值的作用
{
double HorCord, VerCord, Hor_tmp;
HorCord = GetExprValue(Hor_Exp);
VerCord = GetExprValue(Ver_Exp);//根据表达式的语法树计算原始坐标
HorCord *= Scale_x;
VerCord *= Scale_y;//进行比例变换
Hor_tmp = HorCord * cos(Rot_angle) + VerCord * sin(Rot_angle);
VerCord = VerCord * cos(Rot_angle) - HorCord * sin(Rot_angle);
HorCord = Hor_tmp;//进行旋转变换
HorCord += Origin_x;
VerCord += Origin_y;//进行平移变换
Hor_x = HorCord;
Ver_y = VerCord;//返回变换后点的坐标
}//没有返回值
//----------循环绘制点的坐标
void DrawLoop(double Start,//起始
double End,//终止
double Step,//步长
struct ExprNode *HorPtr,//横坐标表达式语法树的根节点
struct ExprNode *VerPtr)//纵坐标表达式语法树的根节点
{
extern double Parameter;
double x, y;
for (Parameter = Start; Parameter <= End; Parameter += Step)//把t在范围内的每一个值带入计算
{
CalcCoord(HorPtr, VerPtr, x, y);//计算要绘制店的实际坐标
DrawPixel((unsigned long)x, (unsigned long)y);//绘制这个点
}
}
//----------计算表达式的值
double GetExprValue(struct ExprNode *root)//参数是表达式的根
{//后续遍历语法树 根据不同的节点类型计算当前根节点的值
if (root == NULL) return 0.0;
switch (root->OpCode)
{
//二元运算符
case PLUS:
return GetExprValue(root->Content.CaseOperater.Left) +
GetExprValue(root->Content.CaseOperater.Right);
case MINUS:
return GetExprValue(root->Content.CaseOperater.Left) -
GetExprValue(root->Content.CaseOperater.Right);
case MUL:
return GetExprValue(root->Content.CaseOperater.Left) *
GetExprValue(root->Content.CaseOperater.Right);
case DIV:
return GetExprValue(root->Content.CaseOperater.Left) /
GetExprValue(root->Content.CaseOperater.Right);
case POWER:
return pow(GetExprValue(root->Content.CaseOperater.Left),
GetExprValue(root->Content.CaseOperater.Right));
case FUNC:
return(*root->Content.CaseFunc.MathFuncPtr)
(GetExprValue(root->Content.CaseFunc.Child));
case CONST_ID:
return root->Content.CaseConst;
case T:
return *(root->Content.CaseParmPtr);
default:
return 0.0;
}//返回值是表达式的值
}
//----------删除一颗语法树
void DelExprTree(struct ExprNode *root)
{
if (root == NULL) return;
switch (root->OpCode)
{
case PLUS://二元::两个孩子的内部节点
case MINUS:
case MUL:
case DIV:
case POWER:
DelExprTree(root->Content.CaseOperater.Left);
DelExprTree(root->Content.CaseOperater.Right);
break;
case FUNC:
DelExprTree(root->Content.CaseFunc.Child);//一元::一个孩子的内部节点
break;
default:
break;
}
delete(root);
}
//----------绘制一个点
void DrawPixel(unsigned long x, unsigned long y)
{
SetPixel(hDC, x, y, red);
}main.cpp
#pragma warning(disable:4996)
#include "semantic.h"
#include <tchar.h>
#define MAX_CHARS 200
extern HDC hDC; // 窗口句柄,全局变量
char SrcFilePath[MAX_CHARS]; // 用于存放源程序文件路径
TCHAR Name[] = _T("函数绘图语言解释器"); // 窗口名
// 检查源程序文件是否合法函数声明
static bool CheckSrcFile(LPSTR);
/* Declare Windows procedure */
LRESULT CALLBACK WindowProcedure(HWND, UINT, WPARAM, LPARAM);
/* Make the class name into a global variable */
TCHAR szClassName[] = _T("函数绘图语言解释器");
int WINAPI WinMain(HINSTANCE hThisInstance,
HINSTANCE hPrevInstance,
LPSTR lpszArgument,
int nFunsterStil)
{
HWND hwnd; /* This is the handle for our window */
MSG messages; /* Here messages to the application are saved */
WNDCLASSEX wincl; /* Data structure for the windowclass */
int i;
/*CTestDlg *pDlg;*/
/* The Window structure */
wincl.hInstance = hThisInstance;
wincl.lpszClassName = szClassName;
wincl.lpfnWndProc = WindowProcedure; /* This function is called by windows */
wincl.style = CS_DBLCLKS; /* Catch double-clicks */
wincl.cbSize = sizeof(WNDCLASSEX);
/* Use default icon and mouse-pointer */
wincl.hIcon = LoadIcon(NULL, IDI_APPLICATION);
wincl.hIconSm = LoadIcon(NULL, IDI_APPLICATION);
wincl.hCursor = LoadCursor(NULL, IDC_ARROW);
wincl.lpszMenuName = NULL; /* No menu */
wincl.cbClsExtra = 0; /* No extra bytes after the window class */
wincl.cbWndExtra = 0; /* structure or the window instance */
/* Use Windows's default color as the background of the window */
wincl.hbrBackground = (HBRUSH)COLOR_BACKGROUND;
/* Register the window class, and if it fails quit the program */
if (!RegisterClassEx(&wincl))
return 0;
/* The class is registered, let's create the program*/
hwnd = CreateWindowEx(
0, /* Extended possibilites for variation */
szClassName, /* Classname */
_T("函数绘图语言解释器"), /* Title Text */
WS_OVERLAPPEDWINDOW, /* default window */
CW_USEDEFAULT, /* Windows decides the position */
CW_USEDEFAULT, /* where the window ends up on the screen */
740, /* The programs width */
490, /* and height in pixels */
HWND_DESKTOP, /* The window is a child-window to desktop */
NULL, /* No menu */
hThisInstance, /* Program Instance handler */
NULL /* No Window Creation data */
);
/* Make the window visible on the screen */
ShowWindow(hwnd, nFunsterStil);
hDC = GetDC(hwnd);
/* pDlg=new CTestDlg();
pDlg->Create(IDD_DIALOG1,this);
pDlg->ShowWindow(SW_SHOW);*/
strcpy(SrcFilePath, "test2.txt");
if (!CheckSrcFile(SrcFilePath)) return 1;
// --------------------------------------------
// 调用绘图语言解释器
Parser(SrcFilePath);
// --------------------------------------------
/* Run the message loop. It will run until GetMessage() returns 0 */
while (GetMessage(&messages, NULL, 0, 0))
{
/* Translate virtual-key messages into character messages */
TranslateMessage(&messages);
/* Send message to WindowProcedure */
DispatchMessage(&messages);
}
/* The program return-value is 0 - The value that PostQuitMessage() gave */
return messages.wParam;
}
/* This function is called by the Windows function DispatchMessage() */
LRESULT CALLBACK WindowProcedure(HWND hwnd, UINT message, WPARAM wParam, LPARAM lParam)
{
switch (message) /* handle the messages */
{
case WM_DESTROY:
PostQuitMessage(0); /* send a WM_QUIT to the message queue */
break;
default: /* for messages that we don't deal with */
return DefWindowProc(hwnd, message, wParam, lParam);
}
return 0;
}
// 检查源程序文件是否合法函数实现
bool CheckSrcFile(LPSTR lpszCmdParam)
{
FILE * file = NULL;
if (strlen(lpszCmdParam) == 0)
{
MessageBoxA(NULL, "未指定源程序文件 !", "错误", MB_OK);
return false;
}
if ((file = fopen(lpszCmdParam, "r")) == NULL)
{
MessageBoxA(NULL, "打开源程序文件出错 !", "错误", MB_OK);
MessageBoxA(NULL, lpszCmdParam, "文件名", MB_OK);
return false;
}
else fclose(file);
return true;
}发扬开源精神方便后人,如果对你有用,hxd点点fork吧
完整项目源码



